データローダを作成するには
- データセットの作成
- データセットからデータローダを作成
の手順で行います。
データローダの概要
ミニバッチ学習を行う際にデータローダをよく利用します。
ミニバッチ学習の構造は下記です。
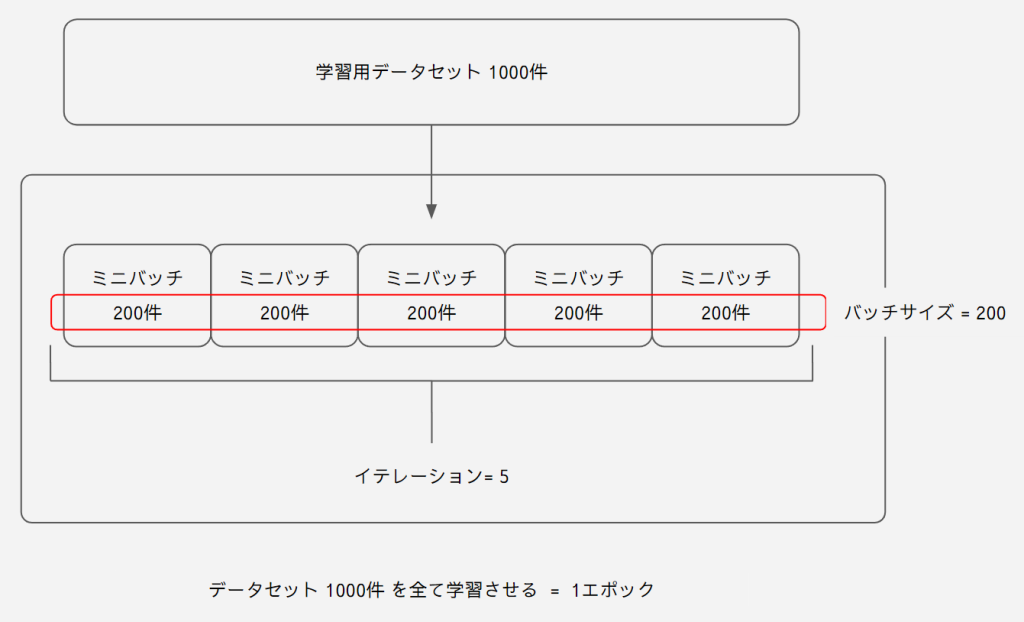
この1エポックの構造を作るのがデータローダです。
アノテーション
データローダを利用するにはアノテーション済みのデータが必要です。
アノテーションとは分類のことです。特に教師あり学習の場合はフォルダで画像を正確に分類しておく必要があります。
画像ファイルやフォルダの名前は何でも構いません。
教師あり学習
教師あり学習の場合は下記のようなディレクトリ構造にしておきます。
ルートフォルダのパスを読み込むことで自動で画像に対してラベルを設定してくれます。
ルート
│
├─ クラス_01
│ ├─ クラス_01 の画像1
│ ├─ クラス_01 の画像2
│ └─ クラス_01 の画像3
│
├─ クラス_02
│ ├─ クラス_02 の画像1
│ ├─ クラス_02 の画像2
│ └─ クラス_02 の画像3
│
└─ クラス_03
├─ クラス_03 の画像1
├─ クラス_03 の画像2
└─ クラス_03 の画像3
教師なし学習
GAN などで利用するには分類は必要ないため、1つのフォルダに画像をまとめます。
この時も ルートフォルダのパスを読み込みます
ルート
│
└─ フォルダ
├─ 画像1
├─ 画像2
├─ 画像3
├─ 画像4
├─ 画像5
└─ 画像6
データセットの作成
データセットは正解とデータがセットになったものです。
訓練 / 検証用データを分けていない場合
import torchvision.transforms as transforms
from torchvision import datasets
# 学習データのパス
data_path = 'hoge/hoge_train'
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# データセットの作成
dataset = datasets.ImageFolder(data_path, transform)
オーグメンテーションは下記を参考にしてください。
今回はリサイズとテンソルへの変換のみ行っています。
trainData_path = 'hoge/hoge_train'は下記のルートのフォルダに当たります。
ルート
│
├─ クラス_01
│ ├─ クラス_01 の画像1
│ ├─ クラス_01 の画像2
│ └─ クラス_01 の画像3
│
├─ クラス_02
│ ├─ クラス_02 の画像1
│ ├─ クラス_02 の画像2
│ └─ クラス_02 の画像3
│
└─ クラス_03
├─ クラス_03 の画像1
├─ クラス_03 の画像2
└─ クラス_03 の画像3
訓練 / 検証用データを分けている場合
訓練用と検証用にデータを分けている場合は下記のように別々にデータセットを用意します。
import torchvision.transforms as transforms
from torchvision import datasets
# 学習データのパス
train_path = 'hoge/hoge_train'
test_path = 'hoge/hoge_test'
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# データセットの作成
train_dataset = datasets.ImageFolder(train_path, transform)
test_dataset = datasets.ImageFolder(test_path, transform)
これは下記のように訓練用と検証用で既にデータを分けている場合です。
訓練用
│
├─ クラス_01
│ ├─ クラス_01 の画像1
│ ├─ クラス_01 の画像2
│ └─ クラス_01 の画像3
│
├─ クラス_02
│ ├─ クラス_02 の画像1
│ ├─ クラス_02 の画像2
│ └─ クラス_02 の画像3
│
└─ クラス_03
├─ クラス_03 の画像1
├─ クラス_03 の画像2
└─ クラス_03 の画像3
検証用
│
├─ クラス_01
│ ├─ クラス_01 の画像1
│ ├─ クラス_01 の画像2
│ └─ クラス_01 の画像3
│
├─ クラス_02
│ ├─ クラス_02 の画像1
│ ├─ クラス_02 の画像2
│ └─ クラス_02 の画像3
│
└─ クラス_03
├─ クラス_03 の画像1
├─ クラス_03 の画像2
└─ クラス_03 の画像3
公開されているデータを利用する場合
下記は CIFAR10 のデータセットを用意した場合のコードです。
from torchvision.datasets import CIFAR10
import torchvision.transforms as transforms
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
train_dataset = CIFAR10("./data", train=True, download=True, transform=transform_train)
test_dataset = CIFAR10("./data", train=False, download=True, transform=transform_test)
データローダの作成
一番重要になるのが バッチサイズです。
バッチサイズでデータローダの構造が決まります。
イテレーションはバッチサイズを決めれば出ます。
エポックはデータローダでは設定しません。
データローダの作成コードは下記です。
# シード値の固定
pl.seed_everything(0)
batch_size = 10
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
データローダに設定できる引数です。
| batch_size | バッチサイズ |
| shuffle | ランダムに順番を変更するかどうか |
| drop_last | 端数のデータを削除するか |
shuffleはデータの順序をランダムにします。
この順序のシード値は下記のコードで固定できます。
pl.seed_everything(0)
訓練 / 検証用データを分けていない場合
訓練と検証用データを分けていない場合はここでデータセットを分割して訓練用データセットと検証用データセットを作ります。
import torch
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import pytorch_lightning as pl
# 学習データのパス
data_path = 'hoge/hoge_train'
# バッチサイズ
batch_size = 1
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# データセットの作成
dataset = datasets.ImageFolder(data_path, transform)
# 学習データに使用する割合
n_train_ratio = 60
# 割合から個数を出す
n_train = int(len(dataset) * n_train_ratio / 100)
n_val = int(len(dataset) - n_train)
# 学習データと検証データに分割
train, val = torch.utils.data.random_split(dataset, [n_train, n_val])
# Data Loader
train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val, batch_size)
データセットの分割 | random_split
# 学習データと検証データに分割
train, val = torch.utils.data.random_split(dataset, [n_train, n_val])
random_splitを使用することでデータセットをランダムに分割できます。
分割するためには引数で分割数を指定する必要があります。
分割数を割合から導出しているのが下記の部分です。
# 学習データに使用する割合
n_train_ratio = 60
# 割合から個数を出す
n_train = int(len(dataset) * n_train_ratio / 100)
n_val = int(len(dataset) - n_train)
こちらもデータローダの作成と同じでpl.seed_everything(0)でシード値を固定します。
学習・検証・テストで3分割する
# 学習データと検証データに分割
train, val, test = torch.utils.data.random_split(dataset, [n_train, n_val, n_test])
例えば上記のコードにすると訓練、検証、テストで3分割できます。
訓練 / 検証用データを分けている場合
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import pytorch_lightning as pl
# 学習データのパス
train_path = 'hoge/hoge_train'
test_path = 'hoge/hoge_test'
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# データセットの作成
train_dataset = datasets.ImageFolder(train_path, transform)
test_dataset = datasets.ImageFolder(test_path, transform)
# シード値の固定
pl.seed_everything(0)
# DataLoaderの設定
batch_size = 10
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)
データローダの構造
print('データローダのタイプ', type(train_loader))
print('全体のデータ量 : ',len(dataset))
print('イテレーション : ', len(train_loader))
検証用コード
import torch
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import pytorch_lightning as pl
# 学習データのパス
data_path = 'hoge/hoge_train'
# バッチサイズ
batch_size = 3
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# データセットの作成
dataset = datasets.ImageFolder(data_path, transform)
# 学習データに使用する割合
n_train_ratio = 60
# 割合から個数を出す
n_train = int(len(dataset) * n_train_ratio / 100)
n_val = int(len(dataset) - n_train)
# 学習データと検証データに分割
train, val = torch.utils.data.random_split(dataset, [n_train, n_val])
# Data Loader
train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val, batch_size)
print('データローダのタイプ', type(train_loader))
print('全体のデータ量 : ',len(dataset))
print('イテレーション : ', len(train_loader))
データローダのタイプ <class 'torch.utils.data.dataloader.DataLoader'>
全体のデータ量 : 100
イテレーション : 20
データローダの構造概要
データローダの構造は下記のようになっています。
上記の構造のため、len(data_loader)でイテレータの数を取得できます。
画像とラベルを取り出す
ミニバッチを取り出すには下記のように取り出します。
# データロダからバッチを取り出す
image_list, label_list = iter(train_loader).next()
print('画像の枚数 : ', len(image_list))
print('ラベルの個数 : ', len(label_list))
print('画像 : ', image_list[0].shape)
print('ラベル : ', label_list[0])
image_list と label_list にはそれぞれバッチ数分のデータが入っています。
検証用コード
import torch
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import pytorch_lightning as pl
# 学習データのパス
data_path = 'hoge/hoge_train'
# バッチサイズ
batch_size = 3
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# データセットの作成
dataset = datasets.ImageFolder(data_path, transform)
# 学習データに使用する割合
n_train_ratio = 60
# 割合から個数を出す
n_train = int(len(dataset) * n_train_ratio / 100)
n_val = int(len(dataset) - n_train)
# シード値の固定
pl.seed_everything(0)
# 学習データと検証データに分割
train, val = torch.utils.data.random_split(dataset, [n_train, n_val])
# Data Loader
train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val, batch_size)
# データロダからバッチを取り出す
image_list, label_list = iter(train_loader).next()
print('画像の枚数 : ', len(image_list))
print('ラベルの個数 : ', len(label_list))
print('画像 : ', image_list[0].shape)
print('ラベル : ', label_list[0])
画像の枚数 : 3
ラベルの個数 : 3
画像 : torch.Size([3, 128, 128])
ラベル : tensor(1)
データローダを回す
実際にデータローダを回してみます。
学習する際にはエポック数でイテレーションを回しますので、データローダをエポック数の for 文で繰り返します。
# エポック で回す
epoch = 2
for i in range(epoch):
print('\n\nエポック数 : ', i + 1)
print('---------------------------------------------------------')
# ミニバッチ(x, t)を取り出す
for j, (x, t) in enumerate(train_loader):
print('イテレーション数 : ', j + 1)
print(' バッチ数 : ', len(x))
print(' 画像 : ', x.shape)
print(' ラベル : ', t, '\n')
検証用コード
import torch
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import pytorch_lightning as pl
# 学習データのパス
data_path = 'hoge/hoge_train'
# バッチサイズ
batch_size = 14
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# データセットの作成
dataset = datasets.ImageFolder(data_path, transform)
# 学習データに使用する割合
n_train_ratio = 60
# 割合から個数を出す
n_train = int(len(dataset) * n_train_ratio / 100)
n_val = int(len(dataset) - n_train)
# シード値の固定
pl.seed_everything(0)
# 学習データと検証データに分割
train, val = torch.utils.data.random_split(dataset, [n_train, n_val])
# Data Loader
train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val, batch_size)
# エポック で回す
epoch = 2
for i in range(epoch):
print('\n\nエポック数 : ', i + 1)
print('---------------------------------------------------------')
# ミニバッチ(x, t)を取り出す
for j, (x, t) in enumerate(train_loader):
print('イテレーション数 : ', j + 1)
print(' バッチ数 : ', len(x))
print(' 画像 : ', x.shape)
print(' ラベル : ', t, '\n')
エポック数 : 1
---------------------------------------------------------
イテレーション数 : 1
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([3, 0, 8, 2, 6, 1, 9, 9, 4, 7, 6, 7, 7, 2])
イテレーション数 : 2
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([3, 6, 9, 2, 6, 0, 0, 5, 1, 9, 7, 5, 2, 5])
イテレーション数 : 3
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([5, 9, 0, 5, 8, 4, 4, 1, 7, 8, 6, 7, 4, 6])
イテレーション数 : 4
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([2, 1, 0, 0, 4, 5, 8, 9, 2, 6, 0, 5, 9, 8])
エポック数 : 2
---------------------------------------------------------
イテレーション数 : 1
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([6, 0, 7, 8, 4, 9, 6, 3, 6, 4, 4, 0, 7, 2])
イテレーション数 : 2
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([3, 0, 5, 0, 7, 3, 1, 9, 8, 4, 5, 1, 7, 2])
イテレーション数 : 3
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([6, 9, 7, 2, 4, 9, 5, 5, 6, 0, 5, 8, 5, 7])
イテレーション数 : 4
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([0, 2, 2, 9, 1, 8, 0, 5, 8, 9, 1, 4, 6, 6])
enumerate 関数
データローダは enumerate を利用して回します。
for j, (x, t) in enumerate(train_loader):
enumerate 関数は要素とインデックスを同時に取得できる関数です。
a = ['a', 'b', 'c', 'd']
b = list(enumerate(a))
print(b)
[(0, 'a'), (1, 'b'), (2, 'c'), (3, 'd')]
上記のようにリストの中身とインデックスがタプルでリスト化されます。
つまり、
print(list(enumerate(train_loader)))
とした場合、
検証用コード
import torch
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import pytorch_lightning as pl
# 学習データのパス
data_path = 'hoge/hoge_train'
# バッチサイズ
batch_size = 14
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# データセットの作成
dataset = datasets.ImageFolder(data_path, transform)
# 学習データに使用する割合
n_train_ratio = 60
# 割合から個数を出す
n_train = int(len(dataset) * n_train_ratio / 100)
n_val = int(len(dataset) - n_train)
# シード値の固定
pl.seed_everything(0)
# 学習データと検証データに分割
train, val = torch.utils.data.random_split(dataset, [n_train, n_val])
# Data Loader
train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val, batch_size)
print(list(enumerate(train_loader)))
[(0, [[1バッチの画像リスト], [1バッチのラベルリスト]]), (1, [[1バッチの画像リスト], [1バッチのラベルリスト]]) ・・・]
となります。このため、
for j, (x, t) in enumerate(train_loader):
上記のコードでは下記のデータが格納されて for 文で繰り返されます。
| j | イテレーションの数 |
| x | 1 バッチの画像リスト |
| t | 1 バッチのラベルリスト |
enumerate を使用せずに回す
イテレーションの中にはデータとラベルの 2つのリストが格納されているため、for 文で回すには変数を2つ用意します。
# エポック で回す
epoch = 2
for i in range(epoch):
print('\n\nエポック数 : ', i + 1)
print('---------------------------------------------------------')
# ミニバッチ(x, t)を取り出す
for x, t in train_loader:
print(' バッチ数 : ', len(x))
print(' 画像 : ', x.shape)
print(' ラベル : ', t, '\n')
検証用コード
import torch
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import pytorch_lightning as pl
# 学習データのパス
data_path = 'hoge/hoge_train'
# バッチサイズ
batch_size = 14
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# データセットの作成
dataset = datasets.ImageFolder(data_path, transform)
# 学習データに使用する割合
n_train_ratio = 60
# 割合から個数を出す
n_train = int(len(dataset) * n_train_ratio / 100)
n_val = int(len(dataset) - n_train)
# シード値の固定
pl.seed_everything(0)
# 学習データと検証データに分割
train, val = torch.utils.data.random_split(dataset, [n_train, n_val])
# Data Loader
train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val, batch_size)
# エポック で回す
epoch = 2
for i in range(epoch):
print('\n\nエポック数 : ', i + 1)
print('---------------------------------------------------------')
# ミニバッチ(x, t)を取り出す
for x, t in train_loader:
print(' バッチ数 : ', len(x))
print(' 画像 : ', x.shape)
print(' ラベル : ', t, '\n')
エポック数 : 1
---------------------------------------------------------
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([3, 0, 8, 2, 6, 1, 9, 9, 4, 7, 6, 7, 7, 2])
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([3, 6, 9, 2, 6, 0, 0, 5, 1, 9, 7, 5, 2, 5])
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([5, 9, 0, 5, 8, 4, 4, 1, 7, 8, 6, 7, 4, 6])
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([2, 1, 0, 0, 4, 5, 8, 9, 2, 6, 0, 5, 9, 8])
エポック数 : 2
---------------------------------------------------------
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([6, 0, 7, 8, 4, 9, 6, 3, 6, 4, 4, 0, 7, 2])
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([3, 0, 5, 0, 7, 3, 1, 9, 8, 4, 5, 1, 7, 2])
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([6, 9, 7, 2, 4, 9, 5, 5, 6, 0, 5, 8, 5, 7])
バッチ数 : 14
画像 : torch.Size([14, 3, 128, 128])
ラベル : tensor([0, 2, 2, 9, 1, 8, 0, 5, 8, 9, 1, 4, 6, 6])
検証用に 1バッチのみを取り出す
上の方で既に行いましたが、文字列を統一させてもう一度書いておきます。
# ミニバッチ(x, t)を取り出す
x, t = iter(train_loader).next()
print(' バッチ数 : ', len(x))
print(' 画像 : ', x.shape)
print(' ラベル : ', t, '\n')
これで 1 バッチのみの画像データとラベルを取り出せます。
検証用コード
import torch
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import pytorch_lightning as pl
# 学習データのパス
data_path = 'hoge/hoge_train'
# バッチサイズ
batch_size = 14
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# データセットの作成
dataset = datasets.ImageFolder(data_path, transform)
# 学習データに使用する割合
n_train_ratio = 60
# 割合から個数を出す
n_train = int(len(dataset) * n_train_ratio / 100)
n_val = int(len(dataset) - n_train)
# シード値の固定
pl.seed_everything(0)
# 学習データと検証データに分割
train, val = torch.utils.data.random_split(dataset, [n_train, n_val])
# Data Loader
train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val, batch_size)
# ミニバッチ(x, t)を取り出す
x, t = iter(train_loader).next()
print(' バッチ数 : ', len(x))
print(' 画像 : ', x.shape)
print(' ラベル : ', t, '\n')
for 文では 1 バッチのみを取り出せない
下記の文ではエラーで止まります。
# ミニバッチ(x, t)を取り出す
for x, t in train_loader[0]:
print(' バッチ数 : ', len(x))
print(' 画像 : ', x.shape)
print(' ラベル : ', t, '\n')
検証コード
import torch
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import pytorch_lightning as pl
# 学習データのパス
data_path = 'hoge/hoge_train'
# バッチサイズ
batch_size = 14
# オーグメンテーション
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
# データセットの作成
dataset = datasets.ImageFolder(data_path, transform)
# 学習データに使用する割合
n_train_ratio = 60
# 割合から個数を出す
n_train = int(len(dataset) * n_train_ratio / 100)
n_val = int(len(dataset) - n_train)
# シード値の固定
pl.seed_everything(0)
# 学習データと検証データに分割
train, val = torch.utils.data.random_split(dataset, [n_train, n_val])
# Data Loader
train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val, batch_size)
# ミニバッチ(x, t)を取り出す
for x, t in train_loader[0]:
print(' バッチ数 : ', len(x))
print(' 画像 : ', x.shape)
print(' ラベル : ', t, '\n')
TypeError: 'DataLoader' object is not callable
ちなみに下記の文でもエラーで止まります。
# ミニバッチ(x, t)を取り出す
x, t = train_loader[0]
データローダの作成を汎用化させる
色々と設定が面倒なのでクラスにまとめて汎用的に使えるようにしています。
データローダーの作成コード
import os
import torch
from torchvision import transforms
from torchvision import datasets
import torchvision.transforms.functional as TF
class DataLoader:
def __init__(self):
# バッチサイズ
self.batch_size = 20
# 画像サイズ
self.image_size = 256
# オーグメンテーション後の画像を保存するか
self.save_transformed_img_status = True
# PIL.Image へのオーグメンテーション
self.pil_augmentation = []
# テンソルへのオーグメンテーション
self.tensor_augmentation = []
# ログの出力
self.log = False
# データセットの分割
# --------------------------------------------------------------------------------------------------------------
# 検証ローダーが必要かどうか
self.val_loader_status = True
# テストローダーが必要かどうか
self.test_loader_status = True
# 訓練データの割合
self.n_train_probability = 50
# 検証データの割合
self.n_val_probability = 25
# パスの設定
# --------------------------------------------------------------------------------------------------------------
self.root_path = 'data'
self.train_name = 'train'
self.val_name = 'val'
self.test_name = 'test'
self.transformed_name = 'transformed'
# オーグメンテーション後の画像データの保存
# ==================================================================================================================
def save_transformed_image(self, dataset, n=0):
# 保存先のパス
self.transformed_path = self.root_path + '\\' + self.transformed_name
for img in dataset:
if not os.path.isdir(self.transformed_path):
os.makedirs(self.transformed_path)
if not os.path.isdir(self.transformed_path + '\\' + str(img[1])):
os.makedirs(self.transformed_path + '\\' + str(img[1]))
pil_img = TF.to_pil_image(img[0])
pil_img.save(self.transformed_path + '\\' + str(img[1]) + '\\transformed_' + str(n) + '.png')
n += 1
if self.log:
print('\nオーグメンテーション後の画像を '+ self.transformed_path + ' へ保存')
def print_loader_info(self, data_loader, label):
print('\n' + label)
# データロダからバッチを取り出す
image_list, label_list = iter(data_loader).next()
print(' イテレーション : ', len(data_loader))
print(' バッチサイズ : ', len(image_list))
print(' 画像情報 : ', image_list[0].shape)
# データローダの作成
# ==================================================================================================================
def create_data_loader(self):
# オーグメンテーションの構築
# --------------------------------------------------------------------------------------------------------------
#if not self.pil_augmentation == None:
self.transform = transforms.Compose(
self.pil_augmentation +
[
transforms.Resize((self.image_size, self.image_size)),
transforms.ToTensor()
]
+ self.tensor_augmentation
)
if self.log:
print(self.transform)
print('\n--------------------------------------------------------------------------\n\n')
# パスの設定
# --------------------------------------------------------------------------------------------------------------
self.train_path = self.root_path + '\\' + self.train_name
self.val_path = self.root_path + '\\' + self.val_name
self.test_path = self.root_path + '\\' + self.test_name
# データセットの作成
# --------------------------------------------------------------------------------------------------------------
dataset = datasets.ImageFolder(self.train_path, self.transform)
if self.log:
print('全体のデータ量 : ', len(dataset))
# オーグメンテーション後の画像を保存
if self.save_transformed_img_status:
self.save_transformed_image(dataset)
# シード値の固定
torch.manual_seed(0)
# 訓練データのみ必要な場合
# --------------------------------------------------------------------------------------------------------------
if not self.val_loader_status and not self.test_loader_status:
train_loader = torch.utils.data.DataLoader(dataset, self.batch_size, shuffle=True, drop_last=True)
if self.log:
self.print_loader_info(train_loader, '訓練データ')
return train_loader
# 訓練データと検証データが必要な場合
# --------------------------------------------------------------------------------------------------------------
elif self.val_loader_status and not self.test_loader_status:
# データセットが読み込める場合
if os.path.isdir(self.val_path):
train_loader = torch.utils.data.DataLoader(dataset, self.batch_size, shuffle=True, drop_last=True)
val_dataset = datasets.ImageFolder(self.val_path, self.transform)
val_loader = torch.utils.data.DataLoader(val_dataset, self.batch_size)
# ひとつのデータセットを 2分割する場合
else:
# 割合から個数を出す
n_train = int(len(dataset) * self.n_train_probability / 100)
n_val = int(len(dataset) - n_train)
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [n_train, n_val])
train_loader = torch.utils.data.DataLoader(train_dataset, self.batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val_dataset, self.batch_size)
if self.log:
self.print_loader_info(train_loader, '訓練データ')
self.print_loader_info(val_loader, '検証データ')
return train_loader, val_loader
# 訓練データと検証データとテストデータが必要な場合
# --------------------------------------------------------------------------------------------------------------
elif self.val_loader_status and self.test_loader_status:
# 〇検証データ 〇テストデータ
if os.path.isdir(self.val_path) and os.path.isdir(self.test_path):
train_dataset = dataset
val_dataset = datasets.ImageFolder(self.val_path, self.transform)
test_dataset = datasets.ImageFolder(self.test_path, self.transform)
# 〇検証データ ☓テストデータ
elif not os.path.isdir(self.val_path) and os.path.isdir(self.test_path):
# 割合から個数を出す
n_train = int(len(dataset) * self.n_train_probability / 100)
n_test = int(len(dataset) - n_train)
train_dataset, test_daset = torch.utils.data.random_split(dataset, [n_train, n_test])
val_dataset = datasets.ImageFolder(self.val_path, transform)
# ☓検証データ 〇テストデータ
elif os.path.isdir(self.val_path) and not os.path.isdir(self.test_path):
# 割合から個数を出す
n_train = int(len(dataset) * self.n_train_probability / 100)
n_val = int(len(dataset) - n_train)
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [n_train, n_val])
test_dataset = datasets.ImageFolder(self.test_path, transform)
# ☓検証データ ☓テストデータ
elif not os.path.isdir(self.val_path) and not os.path.isdir(self.test_path):
# ひとつのデータセットを 3分割する場合
n_train = int(len(dataset) * self.n_train_probability / 100)
n_val = int(len(dataset) * self.n_val_probability / 100)
n_test = int(len(dataset) - n_train - n_val)
train_dataset, val_dataset, test_dataset = torch.utils.data.random_split(dataset, [n_train, n_val, n_test])
train_loader = torch.utils.data.DataLoader(train_dataset, self.batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val_dataset, self.batch_size)
test_loader = torch.utils.data.DataLoader(test_dataset, self.batch_size)
if self.log:
self.print_loader_info(train_loader, '訓練データ')
self.print_loader_info(val_loader, '検証データ')
self.print_loader_info(test_loader, 'テストデータ')
return train_loader, val_loader, test_loader
data_loader の名前で別ファイルにして読み込んで使用しています。
import data_loader
from torchvision import transforms
data_loader = data_loader.DataLoader()
data_loader.log = True
data_loader.batch_size = 20
data_loader.image_size = 256
data_loader.n_train_probability = 50
data_loader.val_loader_status = True
data_loader.test_loader_status = True
data_loader.save_transformed_img_status = True
data_loader.pil_augmentation = [
transforms.RandomRotation(degrees=90)
]
train_loader, val_loader, test_loader = data_loader.create_data_loader()
Compose(
RandomRotation(degrees=[-90.0, 90.0], interpolation=nearest, expand=False, fill=0)
Resize(size=(256, 256), interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
)
--------------------------------------------------------------------------
全体のデータ量 : 100
オーグメンテーション後の画像を data\transformed へ保存
訓練データ
イテレーション : 2
バッチサイズ : 20
画像情報 : torch.Size([3, 256, 256])
検証データ
イテレーション : 2
バッチサイズ : 20
画像情報 : torch.Size([3, 256, 256])
テストデータ
イテレーション : 2
バッチサイズ : 20
画像情報 : torch.Size([3, 256, 256])
オーグメンテーション後の画像を保存
# オーグメンテーション後の画像データの保存
# ==================================================================================================================
def save_transformed_image(self, dataset, n=0):
# 保存先のパス
self.transformed_path = self.root_path + '\\' + self.transformed_name
for img in dataset:
if not os.path.isdir(self.transformed_path):
os.makedirs(self.transformed_path)
if not os.path.isdir(self.transformed_path + '\\' + str(img[1])):
os.makedirs(self.transformed_path + '\\' + str(img[1]))
pil_img = TF.to_pil_image(img[0])
pil_img.save(self.transformed_path + '\\' + str(img[1]) + '\\transformed_' + str(n) + '.png')
n += 1
オーグメンテーションの仕方で結果が変わることがよくあるんですが、
通常のコードでは実際にどういった画像に変換されているかがわかりません。
そこでオーグメンテーション後に画像を保存できるようにしています。
保存しておくことであとからオーグメンテーションについて検証することができます。
下記のパラメータで保存するかどうかを設定できるようにしています。
data_loader.save_transformed_img_status = False

{kind=link}