
コンピュータは 0 か 1 の値しか認識できません。あなたが今こうやってみている文字は、コンピュータにとってみれば 0 か 1 の値の集合体でしかありません。コンピュータを使って聞いている音楽も、見ている映像も、遊んでいるゲームも、触っているポリゴンも、コンピュータ上ではすべて 0 か 1 の集合体です。
今回は文字情報をどうやってコンピュータに渡しているか、またどのように返ってきているのか、というお話です。
後半では python2 と python3 における文字コードの扱いの違いについてお話しします。
unicode_iterals をインポートするかどうかに関して、結論から先に書いておくと私の方針としてはインポートしています。この辺りについても最後の方で触れています。
データ量の単位について
まずは文字を表現するために必要な「データ」についてお話ししていきます。だいぶ遠いところからスタートしますが、避けて通れない点です。
1 ビット【 bit 】
ビットは 0 か 1 で表される 1桁の単位 です。前述したように、パソコンは 0 か 1 しか認識できないため、この 1 ビットがコンピュータが認識できる最小単位です。
コンピュータが扱うことができる全てのデータは、この 0 と 1 の 2種類の内どちらか 1つしか持たない 1桁の値が連続することで構成されており、この個数がどれだけあるかでデータ量が決まります。
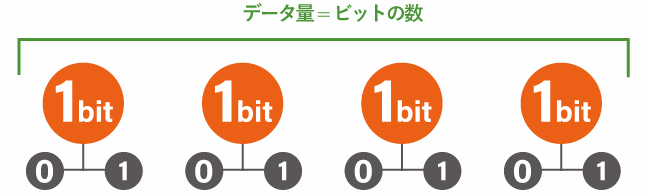
1 バイト【 byte 】
1ビットを8つ並べた単位がバイトです。
バイトという名前は聞いたことがあるのではないでしょうか。○キロバイト、○メガバイト、○ギガバイト、○テラバイトとかのバイトです。
1ビットで表現できるパターンが「0」と「1」の2種類で、それが8つ並びます。表現できるものの種類は 2 の 8乗で 256 パターンです。
例えば、00000000、10000000、01000000、0010000、00010000、00001000、00000100、00000010、00000001、11000000、10100000、10010000、10001000 ・・・・・とひとつずつ数えていくと最大で 256 パターン作ることができます。
このように同じデータが並ぶ列を 配列 といいます。
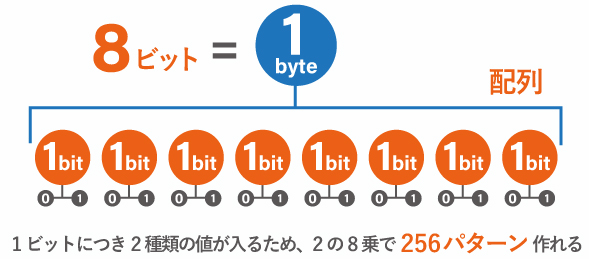
この 256 という数字はよく聞く数字ではないでしょうか。テクスチャサイズやRGB値の色幅の数です。RGB値は 0~255 で 256 パターンあります。
1Byte(バイト)= 8ビット
1KB(キロバイト)=1024バイト
1MB(メガバイト)=1024KB
1GB(ギガバイト)=1024MB
1TB(テラバイト)=1024GB
コンピュータが扱う数値のほとんどが2のべき乗を基準に設定されています。1ビットが2種類の情報を持っているため、2のべき乗がコンピュータにとって計算しやすい数字となります。2 の 10乗が 1024 です。この仕事をしている方にとっては馴染み深い数字だと思います。
ビットの使われ方 | Photoshop の bit/チャンネル
実際にビットがどのように使われているのか、よく利用する Photoshop でみていきます。Photoshop の イメージ > モード の中に 8 bit/チャンネル という項目があります。
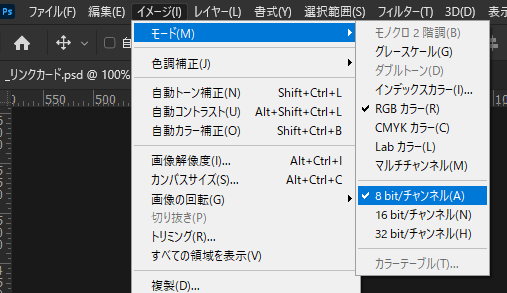
これは 1ピクセルに対する RGBA の各チャンネルの色の階調の幅を指しています。
パターン = 色の数
コンピュータは無限に色を表現することはできません。
1px につき使えるビット数が決まっており、ビット数に応じて使える色の数が決まります。
8 bit /チャンネルは 1ピクセルに対して 8ビット、16 bit/チャンネルは 1ピクセルに対して 16ビット使えます。
8bit の場合は 2の 8乗で 256 個のパターンが作れます。
コンピュータは 1パターンにつき色を 1つ割り当てることができます。そのため、8ビットでは 256 種類の色を扱えます。photoshop ではそれぞれのパターンに 0 ~ 255 の 256種類の値をつけ、RGBA の各チャンネルでそれぞれ使用できるようにしています。
ビット数によって作れる色数の違い
8 bit/チャンネルの場合、Rチャンネル が 256階調、Gチャンネルが256階調、Bチャンネルが256階調 の 16,777,216個の階調が表現できます。(約1,677万色)。さらに透過データであればこれに Aチャンネルの 256 階調が加わります。
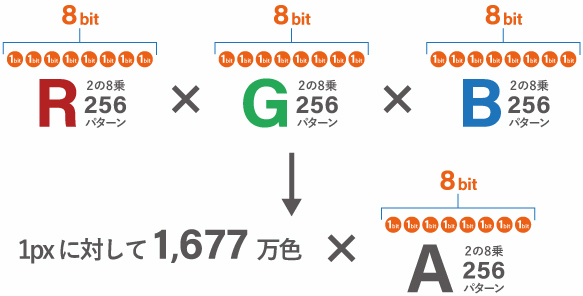
これが 16bit になると 1チャンネルあたり 2 の 16乗で 65,536 階調、3チャンネルで 281,474,976,710,656(約280兆色) の階調を持ちます。
16 bit /チャンネルの場合は 1px に対して280兆色の色 × 6万5千階調のアルファ情報が設定可能です。
1px に対してこの差があるので、3DCG で扱うテクスチャサイズで考えると 16 bit は使用に耐えられない場合がほとんどだと思います。
ただし、レベル補正やトーンカーブを多用して色が壊れる場合などは一旦 16 bit に上げて編集した後に 8bit に戻す、ということが可能です。扱える色幅を一時的に上げられるため、破壊される色調を抑えることができます。
情報量の差
このように、コンピュータで扱う単位においては数字の大きさではなくパターンの数で判断する必要があります。
バイトやビットの数字ではなく、そこから作ることができる パターンの数 が情報量です。
例えば長さの単位でみたとき、7cm と 8cm の差は 1cm です。しかし、7 ビットと 8 ビットでは情報量の差が 2倍です。
7ビットでは 2の 7乗で 128 パターン作れるのに対し、8ビットでは 2 の 8乗で 256 パターン作れます。ビットがひとつ増える毎に、作れるパターンが 2倍ずつ増えていきます。
では、7バイトと8バイトの差はどれくらいなんでしょうか。7バイトは56ビット、8ビットは64ビットです。(1バイトは 8ビット)
下記のページで 2 の 56乗や 2 の 64 乗を計算してみてください。数えたことがない数字がでてきます。
メガバイトやギガバイトになるとさらに作れるパターンの数が増えていきます。
1バイトの差、1メガバイトの差、1ギガバイトの差は、数字の通りの差ではありません。
文字コードについて
繰り返しになりますが、パソコンは 0 か 1 の値しか認識できません。コンピュータで文字を扱うためには、0 や 1 を並べるだけで「 A 」を表現する必要があります。Photoshop で 8ビットの各パターンに色が割り当てられていたように、ビットのパターンに文字を割り当てます。
0 と 1 の集まりで文字を表現する 文字の規格のことを 文字コード と呼びます。
現在は100種類以上の文字コードが存在しますが、今ではほぼ統一されつつあります。ここでは python で扱う「 ASCII 」「Unicode」「UTF-8」の文字コードについて解説していきます。
- 「 Hello world 」コンピュータはこれを認識できない
- 文字を 0 か 1 の配列に変換して認識させる
- 配列のルールを文字コードと呼ぶ
ASCII
ASCII は最も基本的な文字コードとして世界的に普及しています。
1ビットが 7つ並ぶ 7ビットのコードで一文字を表現します。
扱えるのはアルファベットと記号、いくつかの制御コードです。
下記のページで各パターンに割り当てられている文字を確認できます。
アスキーコード表 | 7ビット
例えば ASCII で「 A 」 を表現すると 「 1000001 」となります。
この文字が割り当てられている配列を、コードポイント(符号位置)と呼びます。
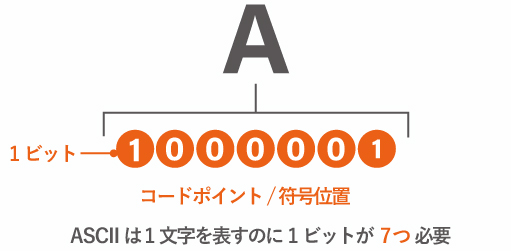
ASCII は 7ビットが正式
ASCII には 7ビットと 8ビットが存在します。
ASCII は 一文字につき 1ビットが7つ並ぶ、 7ビットの文字コードが正規のコードです。古いコンピュータのメモリは貴重だったため、1ビットでも無駄にしないためです。
8ビットはのちに1ビット拡張されたもので、使用できない規格がいくつか存在します。拡張された領域には 7ビットにはなかった半角カナ などが割り当てられています。
ASCIIコード | 8ビット
ASCII のコードポイントを python で確認する
python2 ではデフォルトの文字コードがASCII ですが、python3 では Unicode という文字コードになっています。python3 ではそのまま書くと Uncode として認識されるため、 b (文字列) の形で文字コードが ASCII であることを明示する必要があります。python2 でもこのまま動きますので問題ありません。
次のコードで A を表現するための配列を確認することができます。0b 以下の7桁が表のコードと同じです。
# -*- coding: utf-8 -*- from __future__ import print_function print(bin(ord(b'A'))) # >>> 0b1000001
下記の表と照らし合わせるとコードポイントが合っていることがわかると思います。
アスキーコード表 | 7ビット
ASCIIコード | 8ビット
半角カナ で調べると 8ビットで取得できます。
# -*- coding: utf-8 -*- from __future__ import print_function print(bin(ord(b"ア"))) # >>> 0b10110001
半角カナは 8ビットの ASCII のため、7ビットの A と比べて一桁増えているのがわかります。
進数
文字コードを利用する事で 0 か 1 のみを使って文字を表現することができます。しかし、これだけだと人が扱うには不便です。
「 Hello world 」とコンピュータに認識させたいとき、ASCII のコードポイントに変換すると
「1001000 1100101 1101100 1101100 1101111 100000 1110111 1101111 1110010 1101100 1100100」となります。
ASCIIコード変換機
わずか英単語2つでこの長さです。(計 77個のビットが並んでいます。)
コンピュータはこれでしか理解できませんが、メンテナンスや開発の際に人が バイトやビットを扱うには個数が多すぎて不便です。
そこで、この記述を簡略化させるために 進数 と呼ばれるものを作りました。
ビットには 1桁に 0 か 1 の 2種類の値しか入らない ためここまで数が増えてしまっています。
そこで、0 か 1 以外の数値も入れられるようにしました。
〇進数の〇にはその進数が持てる値の種類の個数が入ります。ここでは 2進数、8進数、10進数、16進数の 4つについてみていきます。
2進数
これまで使ってきた1ビットのことです。0 か 1 の2種類の値しか持てません。
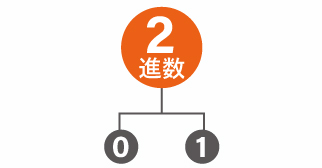
繰り返しになりますがコンピュータはこの 2進数しか認識できません。
「 A 」は「 1000001 」で表現されます。
8進数
1桁に対して 0,1,2,3,4,5,6,7 の 8種類の値のうち一つを使える数です。
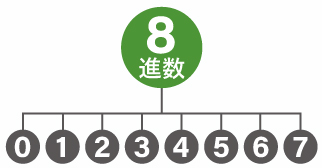
この 8進数に限らず、2進数以外の数値はコンピュータは認識できません。あくまでこれらは人が扱いやすい数値、というだけです。実際にコンピュータで使用するには 2進数に変換してから使います。
8進数で「 A 」は ASCII コードで「 1001 」で表されます。
10進数
1桁に対して 0,1,2,3,4,5,6,7,8,9 の10種類の値のうち一つを使える数です。
10進数で「 A 」は ASCII コードで「 65 」で表されます。
16進数
1桁に対して 0,1,2,3,4,5,6,7,8,9,A、B、C、D、E、F の 16種類の値のうち一つを使える数です。
16進数で「 A 」は ASCII コードで「 41 」で表されます。
進数の変換
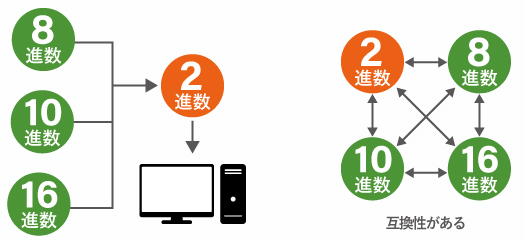
前述しましたが、コンピュータは 2進数以外の数値は読み取れません。
実際にコンピュータで使用する際には 2進数に変換して使用します。また、それぞれの進数には互換性があります。ひとつのものを表すときの桁数が変わるだけで、情報が劣化することはありません。
最近,、量子コンピュータというものが話題になりました。私ごときでは 1%ほども理解できていないんですが、とある記事にこんな一文があります。
通常のコンピュータが扱うビットは「0」か「1」のどちらか一方を表すのに対し、量子コンピュータは「0」と「1」を重ね合わせた状態が取れる量子ビットで演算する。
量子コンピュータ 9000兆倍の破壊力
重ね合わせるってなんでしょうか。
参考サイト:
進数についてのスライド
2進数,8進数,16進数とは? | CMAN
ord 関数と bin 関数
old 関数は 10進数での表記、bin 関数は10進数を2進数に変換する関数です。
0b は その後に続く文字が 2進数であることを表します。
下記の表に10進数でのコードポイントも記載されています。
ASCIIコード | 8ビット
# -*- coding: utf-8 -*- from __future__ import print_function print(ord(b'A')) # 10進数 >>> 65 print(bin(ord(b'A'))) # 2進数 >>> 0b1000001
Unicode
アルファベット 1文字であれば 1バイト( 8ビット)あれば表現できますが、1バイトではすべての日本語はカバーできません。パソコンに漢字を表示させるためには、それぞれの漢字に固有の配列を割り当てる必要があります。
日本語のひらがなやカタカナ、漢字を含めると 8ビット(256パターン)ではとても表現しきれません。
また、世界には日本語以外にも多数の文字が存在します。世界中の人々がその国の言葉でコンピュータを扱うには、すべての言語の文字を表現できる文字コードが必要でした。
そこで生まれたのが Unicode という文字コードです。
Unicode は世界共通で使用できることを目指した文字コード規格で、今ではすでに定番となっています。
Unicode の表記
Unicode における1文字のビット数は最大 21ビット、16進数で4~6桁の配列 になります。世界中の文字を網羅する文字コードのため、ASCII とは桁が違います。
最大 111万4112個(ここの計算方法は普通のべき乗の計算ではないため私程度では理解不能)のパターンを作ることができ、2019年には 13万7929字分が割り当てられています。絵文字なども割り当てられています。
Unicode一覧
下記の表の UTF-16 の列が Unicode のコードポイントです。「 A 」のコードポイントは 3042 です。16進数で表記されていることに注意してください。
Unicode対応 文字コード表
Unicode のコードポイント
文字コードを Unicode で書くには u (文字列) で指定します。
16進数での Unicode のコードポイントを調べる関数が下記です。0x 以下がコードポイントになります。
# -*- coding: utf-8 -*- from __future__ import print_function print(hex(ord(u"あ"))) # >>> 0x3042
hex 関数は 10進数を16進数へ変換する関数です。
0x は その後に続く文字が 16進数であることを表します。
Unicode と utf-8
Unicode が開発され、世界中の文字がひとつの文字コードで扱えます。
しかし、冒頭で説明したように コンピュータは 0 か 1 かの値しか認識できません。16進数は渡せません。
そのため、Unicode 文字をコンピュータが読める 2進数の列(0 か 1 の値が並ぶ配列)に変換する必要があります。
ところが、Unicode は特殊な構造をしています。面(plane)」「区(row)」「点(cell)」と呼ばれる、本職がデザイナーの私ではとても理解不能な計算をします。理解できていないため詳しく解説できず申し訳ないのですが、この Unicode のコードポイントは下記のサイトでできるような単純な計算では2進数に変換できません。
そこで、エンコードと呼ばれる上記の計算とは違う方法で2進数に変換します。
このエンコードにはいくつかの種類があり、Unicode のエンコード方法として最もメジャーなのが「 utf-8 」と呼ばれる変換方式です。
また、コンピュータは 0 か 1 の 2進数の値しか認識できないため、コンピュータが返す文字も 2進数です。そのためこれもコードポイントに変換する必要があります。このコンピュータ → コードポイントの変換をデコードと呼びます。
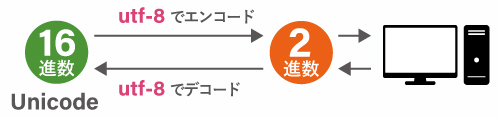
エンコードとデコードの変換方式が異なったとき、コードポイントがずれるため文字化けが発生します。
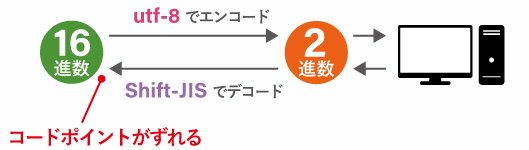
# -*- coding: utf-8 -*-
python2 で冒頭に記述する上記の文は、エンコード/デコードの方法を utf-8 で行うように指定するためのコードです。python3 ではデフォルトの文字コードが Unicode になり、エンコード/デコードもデフォルトで utf-8 になったため、このコードが必要なくなっています。
ASCII のエンコード
ASCII はそもそもが 2進数のため、変換が不要です。
ASCII では 1文字を表現するために 1バイト(8ビット)のデータが必要です。「 Hello world 」は 1バイトが 11個並ぶことで表現されます。ASCII のように1バイトが並ぶ配列を バイト列 と呼ばれます。
文字コードについてお話ししましたが、今回の本題はここではないため、文字集合 や 文字符号化形式 などの難しい単語には触れていません。まだまだお話ししたい内容はあるんですが、ニッチ過ぎると思うのでこの辺りにして本題へ入ります。
参考サイト:
Unicodeコンソーシアム
本当は怖い文字コードの話 | gihyo.jp
文字コードの考え方から理解するUnicodeとUTF-8の違い | ギークを目指して
UTF-8(ユーティーエフエイト)とは?文字コードの仕組みを知れば文字化けでも慌てない | ferret
python2 と python3 の文字コードの違い
maya のバージョンによって python のバージョンが異なります。

python2 と python3 ではデフォルトの文字コードが違っています。
- python2 のデフォルトの文字は ASCII のバイト列
- python3 は全ての文字コードが Unicode で統一
- python3 は標準のエンコード/デコードが utf-8
となっています。
下記のコードは python2 と python3 で結果が違います。
# -*- coding: utf-8 -*-
from __future__ import print_function
import maya.cmds as cmds
selectNode_list = cmds.ls(sl=True)
for selectNode in selectNode_list:
print(type(selectNode))
print(type('テスト'))
python3 の環境では 8行目の selectNode のタイプも テスト のタイプも同じ str です。
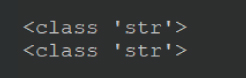
それに対し、python2 ではタイプが異なります。
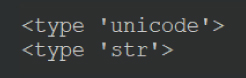
選択中のノード名は「Unicode 型」、「テスト」の文字列は「str 型」とでます。
python3 では文字列の型は str 型に統一されましたが、python2 では文字列型に複数の型があります。
とはいえ上のコードでは特にエラーは起こりません。不具合が起こるのは次のような場合です。
# -*- coding: utf-8 -*-
from __future__ import print_function
import maya.cmds as cmds
selectNode_list = cmds.ls(sl=True)
for selectNode in selectNode_list:
print('\n選択中のノード : ' + selectNode)
python2 の場合、8行目でエラーが起きまて止まります。

python2 の文字列型の違いは文字コードの違いです。
「 + 」で文字と文字を接続しようとしていますが、接続できるのは同じ型のみです。python3 であれば同じ型同士を接続するので問題ありませんが、python2 だと別の型を接続しようとするためエラーがおこります。
つまり、python2 でこの二つの文字コードを揃え、且つ python3 でエラーが起きない コードが必要になります。

str 型 の文字コード
str という文字コードはありません。str は string の略で文字列を意味します。
str 型の文字列の文字コードはその python のバージョンのデフォルトの文字コードです。
python2 の str 型 → ASCII
python3 の str 型 → Unicode
となっています。文字コードが違う場合、連結後のコードポイントが不明になります。エンコードもうまくいきません。そのため、異なる文字コードは連結できません。

文字を unicode 型で記載
文字列の前に「 u 」を付けると Unicode 型になります。
# -*- coding: utf-8 -*-
from __future__ import print_function
print('\n\n\n')
print(type( 'テスト' ))
print(type( u'テスト' ))
python2 では5行目の テスト は Unicode 型になっています。もともと python2 ではこれが日本語の書き方でした。デフォルトの ASCII では日本語を扱えないため、Unicode に変換して使用していました。そのため、今ネットにある maya の日本語の文はほぼ全てu が付いているはずです。
一方、python3 の環境で u を付けた状態でもエラーは出ないため問題はありません。python3 でも u がついたまま使えます。
# -*- coding: utf-8 -*- from __future__ import print_function import maya.cmds as cmds selectNode_list = cmds.ls(sl=True) for selectNode in selectNode_list: print( u'\n選択中のノード : ' + selectNode)
上記のコードは ASCII を Unicode へ変換しています。
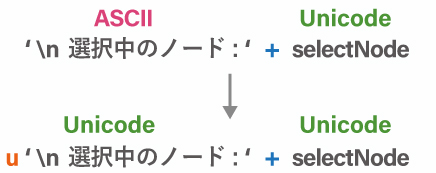
この辺りで疑問がでてくるのではないでしょうか。ASCII では日本語が扱えないのに、連結しなければ使える、というよくわからない状況になっています。この部分は後述します。
str 関数で str 型に変換
str 関数 を使用する方法でも文字コードを統一できます。str 関数は 引数で渡した型を str 型に変換する 関数です。
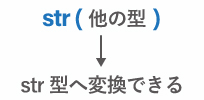
次のコードであれば python2 でも python3 でもエラーが起きなくなります。
# -*- coding: utf-8 -*-
from __future__ import print_function
import maya.cmds as cmds
selectNode_list = cmds.ls(sl=True)
for selectNode in selectNode_list:
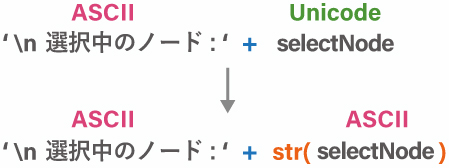
print('\n選択中のノード : ' + str(selectNode) )
8行目の Unicode の文字を ASCII に変換しています。
これも python3 でそのまま使えます。
unicode_literals を使う
future モジュールには python3 と同じように、デフォルトの文字コードが Unicode に設定できる機能が用意されています。それが unicode_literals と呼ばれるものです。future モジュールのインポート文の print_function に続いて記載します。
from __future__ import print_function, unicode_literals
これで str 関数や Unicode 変換を行わなくても 文字コードが Unicode で統一されます。
# -*- coding: utf-8 -*-
from __future__ import print_function, unicode_literals
import maya.cmds as cmds
selectNode_list = cmds.ls(sl=True)
for selectNode in selectNode_list:
print('\n選択中のノード : ' + selectNode)
2行目で unicode_literals をインポートするだけでエラーがなくなります。

python3 と同じ書き方ができるため、当然このまま python3 でも動きます。
print_function の役割
繰り返しになりますが ASCII で日本語は扱えません(半角カナ のみ可)。平仮名や漢字を扱うには 7ビット / 8ビットでは配列のパターンの数が圧倒的に足りません。
アスキーコード表 | 7ビット
ASCIIコード | 8ビット
from __future__ import print_function
print('python2 の時のこの文字コードは何か')
上記の文字コードは ASCII です。
from __future__ import print_function
print('python2 の時のこの文字コードは何か' + u'これは Unicode')
そのため python2 では Unicode と連結できずにエラーがでます。
文字列が ASCII なのに日本語が使える原因は print_function にあります。
from __future__ import print_function
いつも冒頭でインポートしているこのモジュールです。print_function には下記の役割があります。
-
print を python3 と同じ
print() で書けるようにする - python2 で unicode を指定する際に「 u 」を省略できるようにする
python3 と同じ使い方ができるように Unicode を指定する際に「 u 」を省略できるようにしただけで、扱いは ASCII のまま ということです。
from __future__ import print_function
print('python2 の時のこの文字コードは何か')
python2 ではこの文字列の文字コードは Unicode だけど扱いは ASCII です。そのため、何かしらの加工を加えないと Unicode の文字列と連結ができません。
unicode_literals をインポートするかどうか
一見すると unicode_literals を入れるとそれで解決するように見えます。
しかし、このモジュールを使うかどうかは意見が割れます。デメリットもあるためです。
スクエニの佐々木さんが公開されているスライドを置いておきます。
Maya 2022 における Python 3 と 2 の相互運用のノウハウ
このスライドでは unicode_literals はインポートしない、とされています。
理由はスライド内でも解説されていますが、str( python2 だと ASCII )で動作するように設計されたモジュールが多いためです。
(ここの詳しい解説を入れるとさらに長くなるので割愛します)
私はどうしているかというと、インポートしています。
理由はスクエニさんほど開発環境が大きくないからです。そもそも私は TA ではなくデザイナーのため、責任を負うべきツールが佐々木さんに比べると小指の先ほどしかありません。そのため既に軸足が python3 でのツール開発に移行しており、インポートしない理由が特にない、という状況です。
この辺りは自分あるいは会社の軸足が python2 なのか python3 なのか、開発規模はどれくらいの規模で、どの程度 python3 を考慮されたコードになっているのか、といった要素で変わってくると思います。
よくわからない場合は unicode_literals をインポートしておいて、エラーでうまくいかなかった時にはそこだけ外す、という使い方がよいのかなと思います。どうせ数年後には python3 がメインになっています。
このサイトでも日本語を扱う場合は unicode_literals をインポートした状態でコードを書いていきますのでご了承ください。
-
print_function をインポートした場合
python2 の日本語は Unicode だけど扱いが ASCII になる -
Unicode として扱うには頭に u を付けるか
unicode_literals をインポートする
{kind=link}